
How big are the largest software projects in the world today?
By contributor count, most of the biggest open source projects seem to max out in the thousands. Using OpenHub data as of writing, Tensorflow has 3,771, and React Native has 3,041. The Linux kernel 3.5 release in 2012 had 1,1951; in the last six months had 3,1522; and in total is an outlier at 25,038. We can expect many of these contributions to be minor—maybe only tens or hundreds will be regular, major authors.
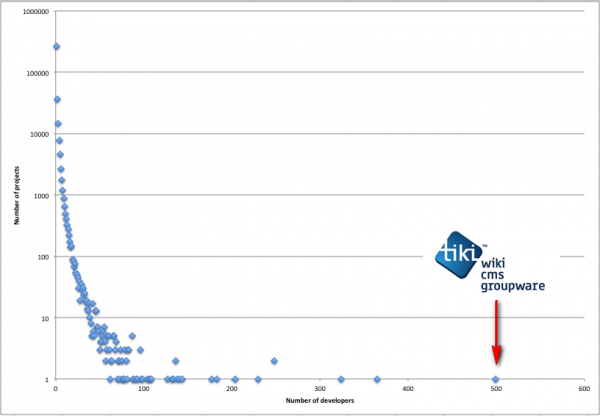
Interestingly, in 2012, the wiki/CMS/intranet software Tiki reached 500 developers with direct commit access.3 This seems high, even for more popular projects today, and at the time it put them far in the lead as the largest project on SourceForge. Apparently they just give access to anyone who asks!4
By total number of dependencies, open source JavaScript packages (considered the most dependency-happy in the software world) seem to max out in the high hundreds.5
I have no doubt the proprietary world will dwarf both of these stats. After all, Microsoft Windows consists of hundreds of gigabytes of revisions spanning decades,6 and is developed inside the 87th largest company in the world, employing over 180,000 people.7
There’s a variety of ways the next millenia could go for humanity, not all pretty. But if we do happen to get the Good Ending, where humans could become a hugely populous, multi-planetary species, it seems obvious that software will only be even more important than it is now. We’ll have far more of it, in bigger codebases written by bigger teams.
What if we had millions or billions of people working on the same piece of software? Or tens or hundreds of thousands of deps?
Developers will probably shudder at the thought, and understandably so: our way of building software simply couldn’t cope. But it’s not like we’re trying—when we run up against things that are too large for us even today, all many engineers can do is say “you shouldn’t do it like that in the first place.”
We are stuck inside tiny, tiny abstractions like processes, files, and environments, which make large programs difficult to develop. Even trends like microservices exist largely because some decompositions are more difficult within a software unit than they are between them. Large teams find it too challenging to coordinate around a single program.
Namespaces are in short supply: in many languages, you’d better hope you don’t need to import two dependencies which have the same name, or link two libraries which have a common symbol. Or depend on two different versions of the same package. (And even when this is possible, good luck using types from one version with functions from another: concepts like backwards-compatibility only exist at the module level, not within a program or type system.)
You’d better hope that you don’t need to implement two Go interfaces which share a method name on the same type. You’d better hope that, if a resource like a port or framebuffer can only be acquired by one thing, that only one part of your program does so, or that all parts of it are made to use the same interfacing layer.
There are some interesting projects which are thinking about software on much larger scales:
-
The Unison programming language associates each definition in the source code with its own globally-unique ID. Changing code creates new IDs. This eliminates all forms of dependency clashing; allows incredibly fine-grained build caching; and also makes it trivial to distribute code across machines, since we can communicate exactly the right code and typed data in exactly the right form. Code is no longer made of written text in files, but rich data structures stored in a database.
-
Twizzler, a research OS, replaces the concept of pointers with global IDs. The problem with pointers is that data referenced by one is completely specific to the process dereferencing it, so they are unsuitable for sharing in any larger context. IDs on the other hand can have a single meaning at a universal level. We can even use them to reference both hard storage and memory, completely eliminating that distinction.
-
Dark lets you write internet services with no infra or deployment concerns, à la serverless functions. It has its own structured code editor with core support for deploying multiple versions of functionality via feature flags. There are no dev branches or dev environments with Dark; you just work on your own changes in your own sandboxed branch of prod, gated by private flags.
When we can address code at such granular levels as individual definitions and functions, I think the concept of “releasing,” and the module or package as the “unit of software” is only going to fade.
Where internal and external imports are currently treated differently, since externals have versioning and package management concerns, they will start to look exactly the same.
Git/VCS might be made redundant by versioned, non-textual source code.
Software ecosystems might start to look more like highly interconnected webs of code, with interfacing happening on a much finer-grained level.
Why leave so many composability issues to hope, and effectively limit the scale of a software unit? These problems and trade-offs aren’t laws of physics. It’s likely that one day, collaboration efforts will be so large that ignoring these problems won’t cut it.
-
$ git clone --shallow-since 2021-12-10 'git@github.com:torvalds/linux.git' ... $ cd linux/ $ git shortlog -sn | wc -l 3152 -
https://tiki.org/article370-Tiki-reaches-500-contributors-with-commit-access ↩
-
https://gist.github.com/anvaka/8e8fa57c7ee1350e3491#file-02-with-most-dependencies-md ↩
-
https://arstechnica.com/information-technology/2017/02/microsoft-hosts-the-windows-source-in-a-monstrous-300gb-git-repository/ ↩
-
https://companiesmarketcap.com/largest-companies-by-number-of-employees/ ↩