
This is a series about a research rabbit hole I’ve been going down over the last year or so, about a kind of incremental programming approach for games, UIs, and more. In this part we’ll cover the basic ideas behind it, what incremental means here, and why I’ve been so interested in it; in later posts, I’ll show you my implementation of the ideas and some demo code to demonstrate how easy it is to implement such a system yourself.
Our story begins with a certain type of program whose task is to “maintain state over time.” Web apps, games, interactive visualisation tools—these types of program are characterised by
- running continuously
- continually receiving inputs (e.g. from mouse and keyboard) which are used to modify the “state.”
The “state” in this case could refer to web page content, game data (such as entity positions or score), vertex data, etc.—anything that changes over time as the program runs.
The code structure for such programs is actually pretty similar. Typically you have two main types of code:
- initial setup code, like loading resources, initialising objects, setting up events
- “update code” e.g. processing mouse and keyboard inputs, or a timed update loop; typically modifies already-established data
The main idea I want to focus on is the fact that, as your program grows, the update code gets very spread out. I find I quickly have dozens of event handlers, each of which can change any aspect of the program state. It becomes very difficult to work out in what order anything happens, or what state anything is in at a given point of time. Annoying consistency issues keep cropping up:
- our game loads a level, which sometimes calls some player code, but the player isn’t initialised properly yet, so the program crashes
- we show old information because we unhide a UI element but forget to refresh its contents
- the player changes size but their collisions don’t update
- we load a new map but it doesn’t reset the weather system, so we have some inconsistent mix of two maps
// ...
case RING:
theItem->enchant1 += enchantMagnitude();
updateRingBonuses();
if (theItem->kind == RING_CLAIRVOYANCE) {
updateClairvoyance();
displayLevel();
}
// ...
This excerpt from Brogue has all the smells of “update code”—after changing the enchant property of a ring item, we have to call updateRingBonuses() to trigger a further update to the player’s ring bonus stats. There are even more updates to be done for the clairvoyance ring. And this is a simple example; often the chain of dependencies is much harder to see.
You know what code doesn’t have this problem? Initial setup code. Everything starts in a known state (uninitialised) and it runs once in a known order. We can just follow it line-by-line. It would be nice if we could write our whole program like that, in some kind of enormous setEntireState() function which specifies all our state in one go. Then we could just keep re-running it.
The issue is it would be way too slow to constantly reinitialise everything when only the tiniest thing changes. So, what if we could somehow only run the parts of it that actually need changing? We could eliminate almost all update code and associated bugs; most “updating” would just be done by refreshing the relevant parts of the setup code. This is what we would call incremental: it only recomputes the required changes. We would get the clarity of setup code without the drawbacks.
Skipping code
Let’s explore this idea of running only some parts of setup code. Suppose we have written a setEntireState() function. It makes some sub-calls to other setup functions.
- We can, in theory, skip making a certain sub-call if its inputs aren’t different from the last time it was run.
- We can, in theory, start executing it part-way through the setup, if data is only changed for a certain sub-part. (We need to make sure we re-run all code which depends on it.)
We might imagine it something like this:
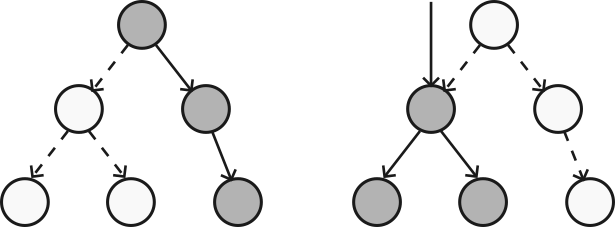
The tree represents a call tree of setEntireState(), with the child nodes representing the sub-functions it calls. Left illustrates skipping a sub-call; right illustrates starting at it.
Now, an observation: the right-hand-side diagram is actually wrong in general, because it doesn’t consider that functions can have return values. If the highlighted sub-tree returns a value, then we have also re-run the code which depends on that value, which requires going back up the tree.
This is a problem, because we want to think of our setEntireState() as a big tree of sub-function calls so that we can skip branches of it. However, in general, the data flow isn’t a tree at all; it’s actually one big snake that traces up and down the tree. See the left diagram:
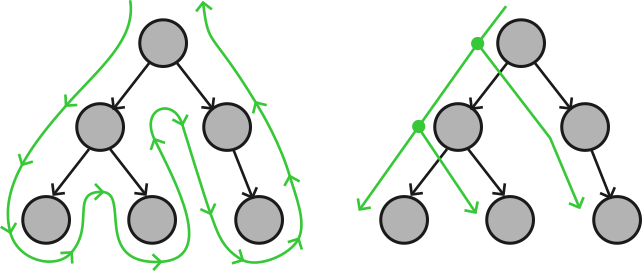
Left: The data flow, in green, if all sub-functions return values. Right: the data flow if no sub-functions return values.
This makes functions without return values quite special. They are “one-way” instead of “two-way,” as in, they only take inputs “down” and no outputs “up.” Hence, they break up the data flow and turn it into an isolated tree. If we start executing at a function which returns nothing, we never need to go back “up” above it.
Suddenly, React
Let’s talk about React real quick.
React is a web framework where you describe the entire content of your page by specifying a dynamic tree of HTML. You do this with functions, called components:
function MyButton() {
return (
<button>
I'm a button
</button>
);
}
function MyApp() {
return (
<div>
<h1>Welcome to my app</h1>
<MyButton />
</div>
);
}
Rendering <MyApp /> produces the HTML tree:
<div>
<h1>Welcome to my app</h1>
<button>I'm a button</button>
</div>
If your tree changes in response to input (i.e. your components return different children) then React changes only the HTML necessary to match the new tree. It does this in two ways:
- if a component is in the same place in the tree as last time, with the same arguments, React skips processing it
- when a components receives new input, then React begins processing at that point in the tree, skipping any components above
Sound familiar? These are exactly the two methods of skipping code that we discussed above! Despite being used for web pages, at its core, React highly resembles a generic incremental programming framework.
Components are those functions without return values that we mentioned before. (Yes, without return values: they may have a return statement, but this is a trick. Components don’t return values up to parent components—the return goes back to the core system. What they return is more like a description of what components React should process next. Essentially, return acts like a special kind of function call. In React, data is never really returned “up” the tree of components; it always flows down.)
Conclusion
The exciting idea here is that React and other reactive web frameworks have proven to be very valuable for creating complex, highly interactive apps. It’s a good sign we can take this idea of incremental setup code into new territories and expect similar improvements.
In part 2, we’ll go over a very different implementation of my own, which is simple to implement, not tied to HTML, and even supports some kinds of data flow which aren’t possible in React. (Make sure to subscribe to the blog for an email when it’s out 📩)
Acknowledgements: This post is a sort-of-rewrite of my previous article React is more than UI—it’s a side-effect framework, which is itself heavily inspired by Steven Wittens’ Climbing Mount Effect series.